

데이터베이스에서 인덱스는 성능 향상의 열쇠라고 할 수 있을 정도로 핵심적인 요소 중 하나이다. 인덱스가 무엇이고, 어떻게 적용되어 있는지 알아보자.
인덱스란?
추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
인덱스를 쓰는 이유
만약 다음과 같은 기본적인 조회 쿼리문이 있다고 해보자.
SELECT *
FROM UESRS
WHERE NAME = "GAMJA";WHERE문을 통해 NAME 열을 조회할 때, 만약 단순히 완전탐색(Full scan)을 한다면 데이터의 개수만큼의 시간이 걸릴 것이다. 즉 데이터의 개수가 N개라면 시간복잡도는 O(N)이 된다. 이는 데이터가 많아지게 되면 쉽게 부하가 올 수 있을 것이다. 이를 인덱스를 통해 좀 더 효율적인 방법으로 개선한다.
즉, 인덱스는 조건을 만족하는 튜플들을 빠르게 조회(SELECT)하기 위해, 혹은 빠르게 정렬(ORDER BY)하거나 그룹화(GROUP BY)를 하기 위해 사용한다.
인덱스 구현 방법
인덱스를 구현하는 데에는 다양한 자료구조가 활용될 수 있는데, 대표적으로 해시 테이블과 B+ Tree가 이용된다.
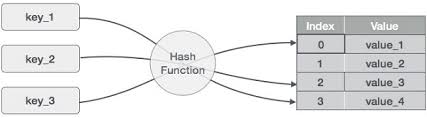
1. 해시 테이블 (Hash table)
해시 테이블은 Key: Value를 갖고 있어 빠른 데이터 조회가 장점인 자료구조다. 시간복잡도 O(1)의 성능을 자랑할만큼 우수하다. 하지만 해시테이블이 데이터베이스에서 사용될 때 치명적인 단점이 존재하는데, 다음과 같다.
1. Rehashing에 대한 부담 (데이터가 늘어날 때마다 리해싱해주는 것에 대한 오버헤드 발생)
2. equality 비교만 가능, range 비교 불가능
3. 멀티컬럼 인덱스의 경우 전체 attributes에 대한 조회만 가능
특히 2번의 이유로 인해 DB 사용 시 많은 것들에 제약이 생긴다. (범위 조회, 포함 여부 등) 그래서 대부분의 DBMS에서는 B+ Tree가 일반적으로 채택되어 사용된다.
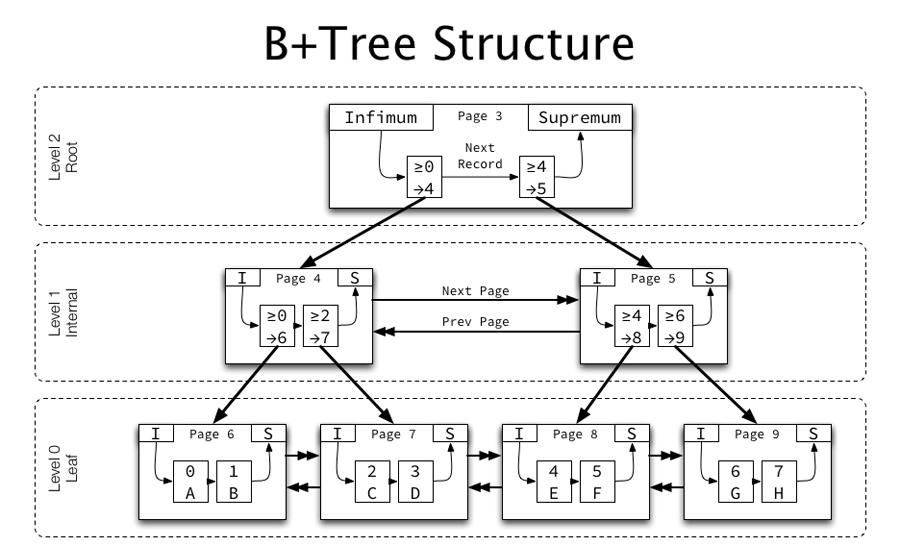
2. B+ 트리 (B+ Tree)
B+ 트리는 DB의 인덱스를 위해 B-Tree를 개선시킨 자료구조이다. 리프 노드에만 데이터를 저장하고, 키 값의 중복을 허용하지 않으며 리프 노드 간의 연결을 통해 탐색의 효율성을 높였다.
DB에서 인덱스가 적용된 컬럼에 대해 부등호 연산을 활용한 순차 검색 연산이 자주 발생한다. 따라서 B+Tree 는 B-Tree의 리프노드들을 LinkedList로 연결해 순차 검색의 효율성을 증대시켰다.
따라서 B+ 트리는 O(logN)의 시간복잡도를 가졌지만 해시 테이블보다 범용성 측면에서 훌륭하기 때문에 DB 인덱싱에 보다 적합한 자료구조가 되었다.
인덱스의 장단점
장점
- 테이블을 조회하는 속도가 빨라지며, 그에 따른 성능 향상을 기대할 수 있다.
- 시스템 오버헤드를 줄일 수 있다.
단점
- 인덱스가 많아지면 테이블에 변경이 일어날 때마다 인덱스도 변경되기 때문에 오버헤드가 발생한다.
- 인덱스 또한 저장 공간을 차지한다. (약 전체 용량의 10%)
특히 이미 데이터가 몇 백만 건 이상 있는 테이블에 인덱스를 생성하는 경우 시간이 몇 분 이상 소요될 수 있고 DB 성능에 안좋은 영향을 줄 수 있음에 주의해야 한다.
Full scan이 더 좋은 경우
인덱스에 대해 알아보았지만 오히려 Full scan을 사용하는 것이 좋은 경우도 존재하는데, 다음과 같은 상황들이다.
- 테이블에 데이터가 조금 있을 때 (몇 백, 몇 천건 정도)
- 조회하려는 데이터가 테이블의 상당 부분을 차지할 때
물론 DBMS는 똑똑하기 때문에 Optimizer가 full scan을 할지, 인덱싱을 할 지 알아서 판단해준다. 👍
Reference
https://cheonmro.github.io/2018/11/04/what-is-hashtable/
https://www.ntfs.com/refs-architecture.htm
'CS 지식 > Database' 카테고리의 다른 글
| [DB] 트랜잭션 (Transaction) (0) | 2024.05.01 |
|---|---|
| [DB] 정규화 (Normalization) (0) | 2024.01.24 |